
He utilizado C++ de forma ininterrumpida durante los últimos diez años, y se ha convertido en una herramienta indispensable en mi vida académica y profesional. La primera vez que interactué con C++ fue cuando comencé a practicar programación competitiva; en ese momento lo entendía como “C con magia”. La transición no fue difícil en términos de sintaxis, pues ya conocía bien C, pero me costó dejar de usar C tal cual lo conocía. Aún no me sentía como alguien capaz de hacer “magia” con este nuevo lenguaje.
C++ te invita a interactuar con la memoria. Por ejemplo, si tengo una lista unidireccional (en la que cada nodo tiene solo un puntero al siguiente nodo de la lista) y quiero eliminar los nodos que cumplen cierto criterio, puedo agregarle un puntero backward y hacer la separación con el método usual: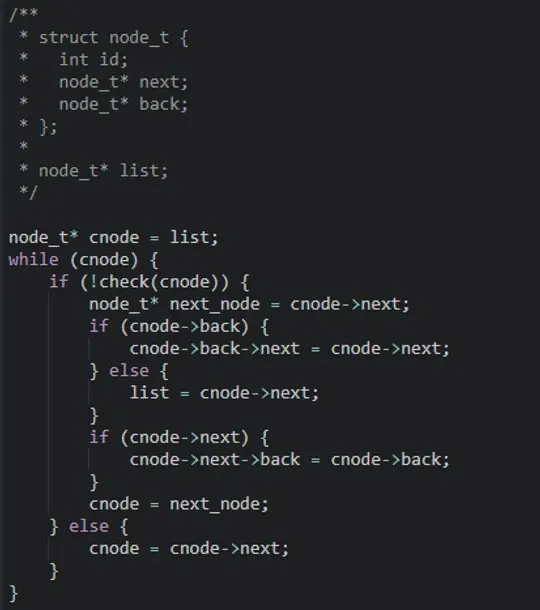
En este código se eliminan nodos específicos, actualizando los punteros back y next.
Esto incurre en un mayor uso de memoria y en un algoritmo con más casos bordes. Sin embargo, un usuario veterano de C++ lo hará utilizando un doble puntero:
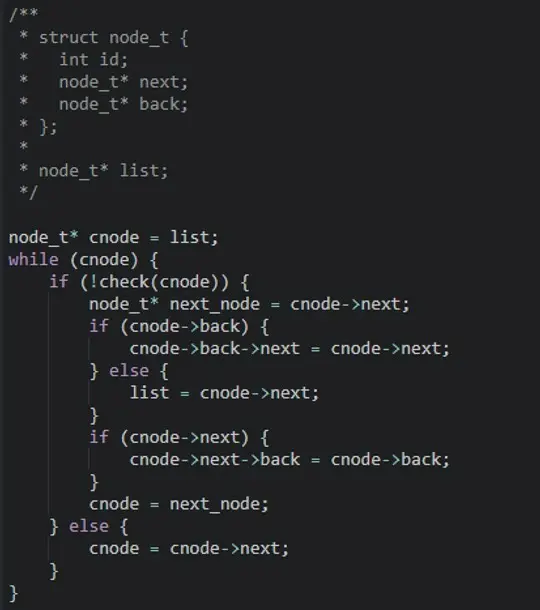
Aquí se usa una versión simplificada con doble puntero. Nota que, en ambos códigos, se omitió la liberación de la memoria, ocupada por el nodo eliminado. El código anterior es imposible de concebir en Python o JavaScript sin usar más memoria o más pasos lógicos.
Cuando empecé en la programación competitiva, mis primeros coaches no se centraron en enseñarme las bases del lenguaje, sino en transmitirme los algoritmos y estructuras que consideraban fundamentales: teoría de grafos, algoritmos voraces y programación dinámica, esta última presentada como una herramienta poderosa, aunque inicialmente intimidante. Recuerdo particularmente cuando me mostraron el código del algoritmo de Dijkstra, extraído del libro Competitive Programming 3.

El algoritmo de Dijkstra (Halim et al., Competitive Programming 3) hace uso de ciertos define, como vi para vector de enteros o INF para un número suficientemente grande. El algoritmo es corto y muy eficiente.
Fue así que, gracias a la programación competitiva, comencé a desarrollar un gran interés por C++. Un día, entrenando en la biblioteca de la universidad, me encontré con el siguiente problema geométrico: dado un monitor de 1024 x 1024 píxeles y una secuencia de k círculos con radios variables, se debía calcular cuántos píxeles se pintaban. El enfoque más directo requería, en el peor de los casos, O(k·n²) operaciones. No logré resolverlo en ese momento, pero al regresar de esa primera mundial recordé el problema y encontré una solución más eficiente, en O(k·n + n²).
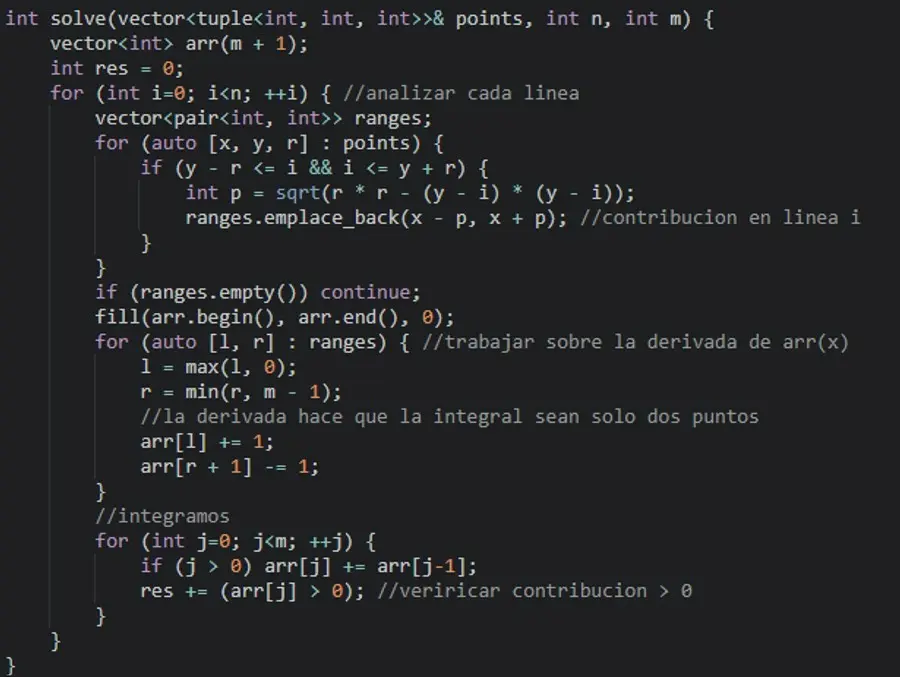
La solución al problema del monitor y los círculos muestra que el símbolo & en la firma de la función indica que el vector se pasa por referencia; al usarlo, se hace una autorreferencia, como en Python, pero mejor. Por otro lado, se puede declarar una variable con la palabra auto, sin necesidad de conocer su tipo exacto.
Posteriormente conocí a Marco Caseres, el entrenador que me llevó al mundial. Marco tenía el propósito de demostrar que la Facultad de Sistemas de la UNI no era la única que podía destacar en programación competitiva. Fue un mentor dedicado, con una gran capacidad para explicar los temas. Era un adicto a los problemas voraces y, bajo su guía, aprendí los fundamentos que antes me faltaban y, finalmente, aprendí a ser “un mago”.

El capítulo 1 del libro Matters Computational de Jörg Arndt, este libro es uno de mis favoritos; se enfoca en algoritmos con una fuerte carga teórica matemática, implementados en C++ y aprovechando al máximo las capacidades del lenguaje.
Una de las primeras clases de Marco fue el manejo de bits. Por ejemplo, cuando se requiere calcular y almacenar la suma de elementos en cada subconjunto de un conjunto de tamaño n, se generan 2ⁿ subconjuntos. En C++, a diferencia de otros lenguajes como Python, es sencillo y eficiente gestionar esa memoria sin recurrir a estructuras como diccionarios, que incurrirían en un factor logarítmico de complejidad computacional, simplemente utilizando arreglos indexados por máscaras de bits.
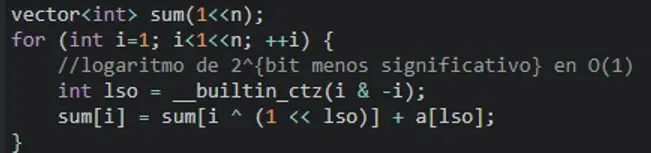
Este código para sumar subconjuntos hace un uso eficiente de la memoria: sorprendentemente, la memoria utilizada es exactamente la que se observa, es decir, 2ⁿ, multiplicado por los 4 bytes que ocupa cada entero. Nada más, nada menos.
Para mi última mundial, tuve cerca de cinco entrenadores en simultáneo, cada uno con enfoques y especialidades distintas. Gracias a esa amplia formación, logré clasificar a mi segunda mundial. Recuerdo especialmente un problema de teoría de juegos en el que debía seleccionarse una mano de cartas con la que se pudiera ganar en el 80 % de las partidas, considerando que el oponente podía usar cualquier estrategia. Fue la primera vez que implementé un algoritmo genético, diseñando una función de evaluación específica para ese contexto.

La función de costo del algoritmo evolutivo para el problema de cartas refleja una de las grandes ventajas de C++: no es necesario forzar la eficiencia, porque ya está implícita. Siempre que programaba estos algoritmos pesados, tanto de inteligencia artificial como, en este caso, genéticos, en lenguajes más amigables, tenía que pensar en la vectorización y en la gestión de memoria. No mucho más lejos, recuerdo un día en que estaba gastando 72 GB de memoria tras una recursión; en C++, no llegaba ni a un gigabyte.
Actualmente me encuentro en la mitad de un doctorado en optimización combinatoria; todo el proyecto lo tengo en C++, con alrededor de 40 mil líneas de código que debo mantener. El problema que investigo es el Single Machine Scheduling Problem with Setup Times.

[Definicion del problema SMSP with Setup Times]
Mi enfoque actual es a través de algoritmos combinatorios; en particular, utilizo algunas variantes de un algoritmo llamado Successive Sublimation Dynamic Programming.
Hasta hoy, creo que C++ ha sido la mejor opción para implementar este algoritmo, sobre todo porque necesito interactuar intensamente con la memoria. Una de las referencias en el estado del arte para este problema es el trabajo realizado por Shunji Tanaka sobre el Single Machine Scheduling Problem With Idle Times, desarrollado completamente en C, con cerca de 20,000 líneas de código, lo que refleja la complejidad y el nivel de detalle requeridos en este tipo de problemas.
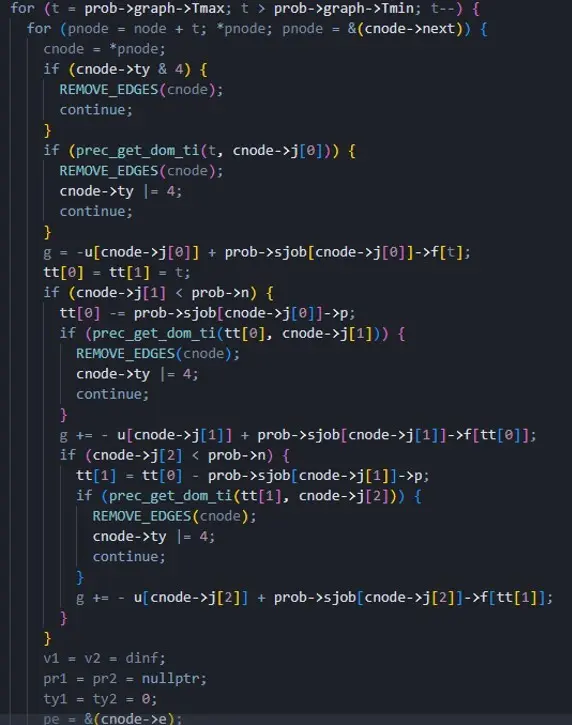
El código de Shunji Tanaka incluye la función “Lagrange Relaxation without (2 + 1)-cycles and space modifiers (LR2m)”, donde una relajación lagrangiana es una versión modificada del problema en la que algunas restricciones se transforman en parte de la función objetivo. La restricción de no permitir ciclos de longitud 3 significa que una secuencia solución no puede tener elementos repetidos en bloques de tres. Asimismo, los modificadores de espacio se refieren a que se fija una cantidad exacta para algunas variables.
Para mí, C++ es una herramienta que combina eficiencia y control de memoria. A lo largo de los años he aprendido a manipular desde estructuras muy sofisticadas hasta manipulado detalles de bajo nivel, como vectorización o el manejo de buffers. Aunque, sin duda, es un camino largo, C++ me ha moldeado la forma de pensar y me ha permitido comprender mejor el funcionamiento interno de un computador, así como ayudado en mi lógica del día a día, y en retrospectiva, creo que fue la mejor elección para empezar (aunque empecé en C, digamos que es lo mismo). Actualmente, soy un usuario activo de C++23, y esperando la siguiente versión que debería ser la 26.
Miguel Alessandro Mini Huambachano
Estudiante PhD UNICAMP
Mundialista ICPC